
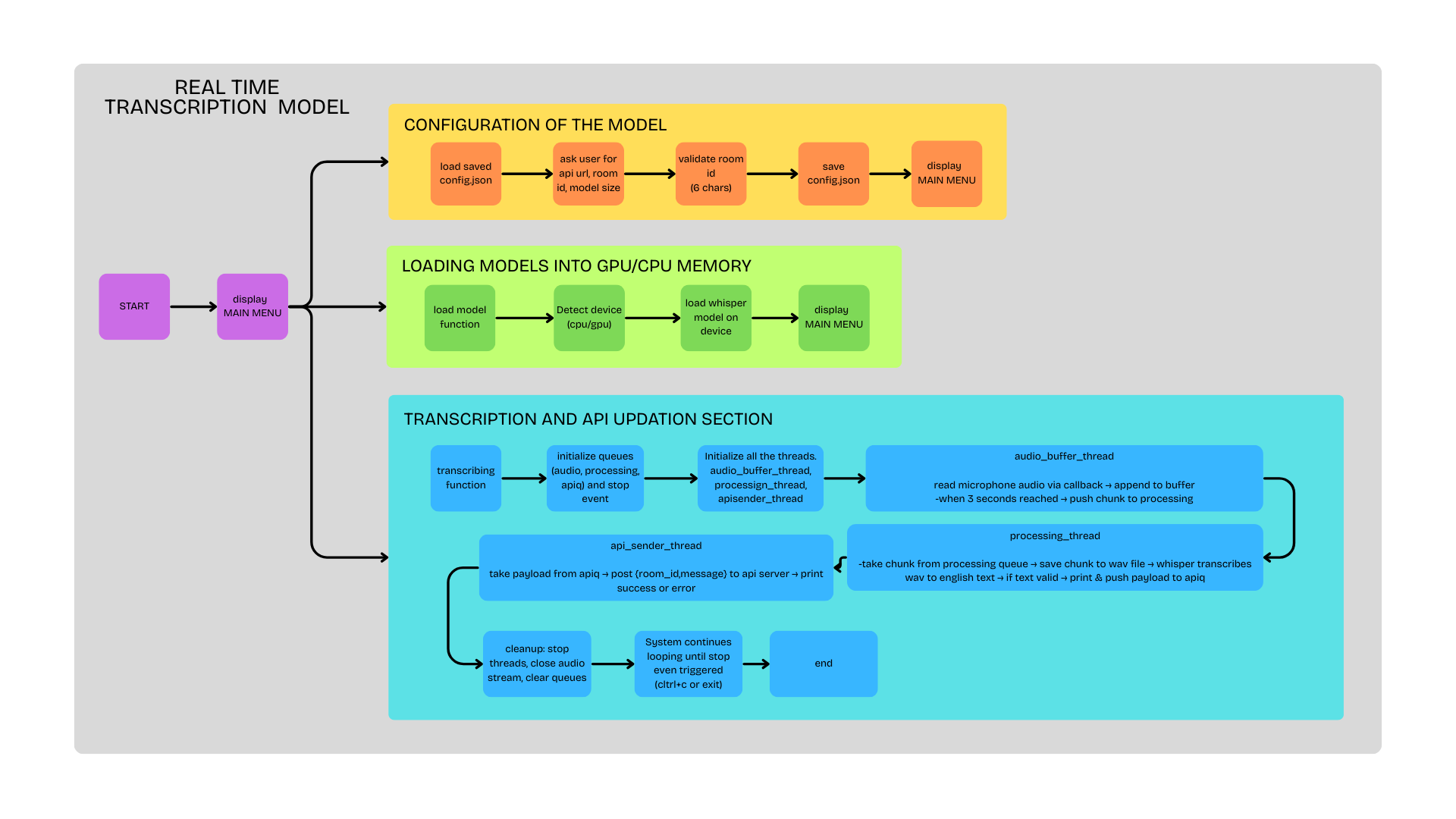
EchoVault is a real-time transcription service that captures audio from a user’s microphone, transcribes it using OpenAI’s Whisper model, and displays the text live on a web interface. The system features a decoupled Python backend and a Next.js frontend that communicate via a REST API and Server-Sent Events (SSE) for live updates.
Backend
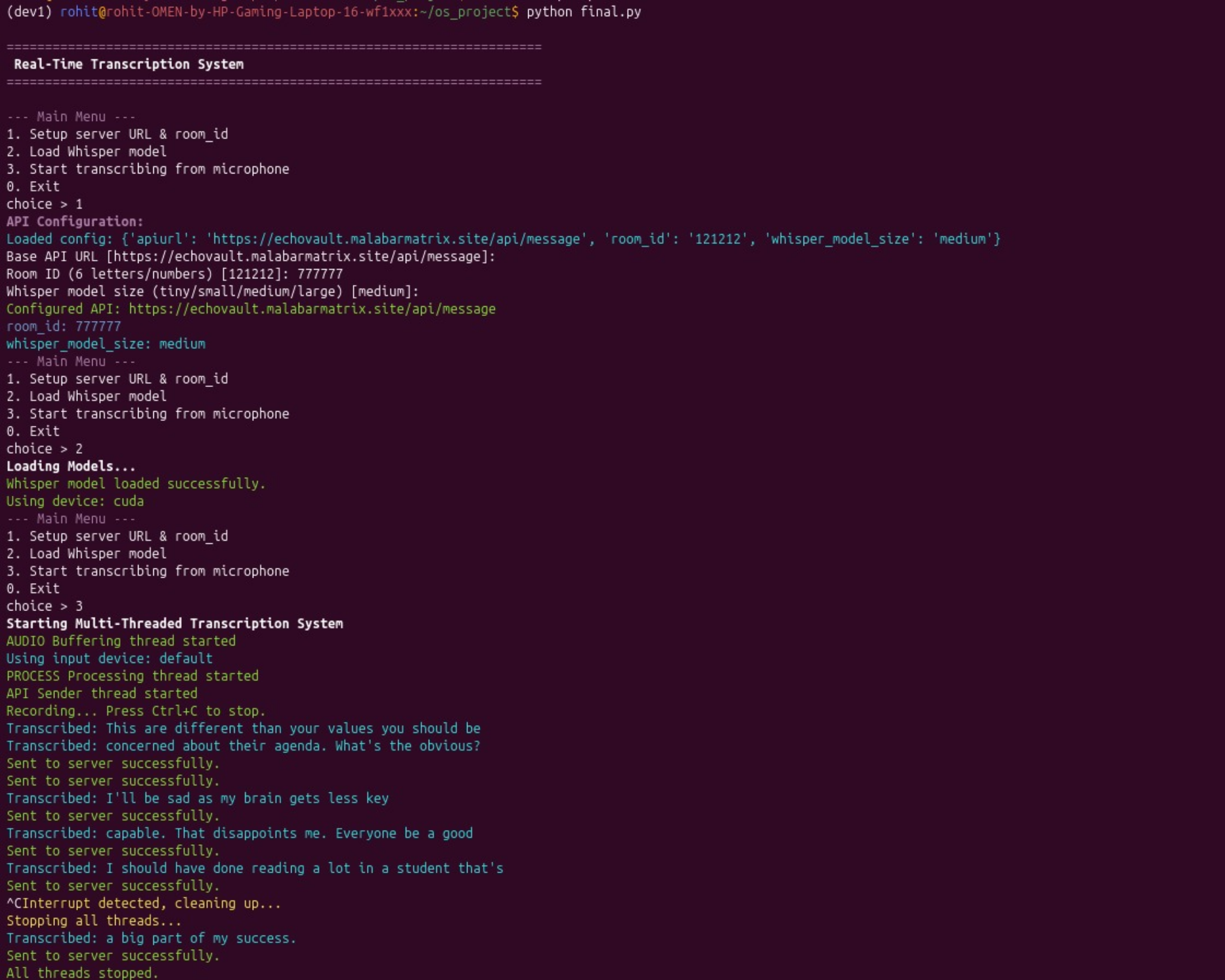
The backend is a standalone, multi-threaded Python script. It uses three concurrent queues for a non-blocking pipeline: one for raw audio data (audioq), one for 3-second chunks ready for transcription (processingq), and one for transcribed text ready to be sent to the frontend (apiq). It captures audio using sounddevice, transcribes it with the Whisper AI model, and sends the resulting text to the Next.js API.
Frontend
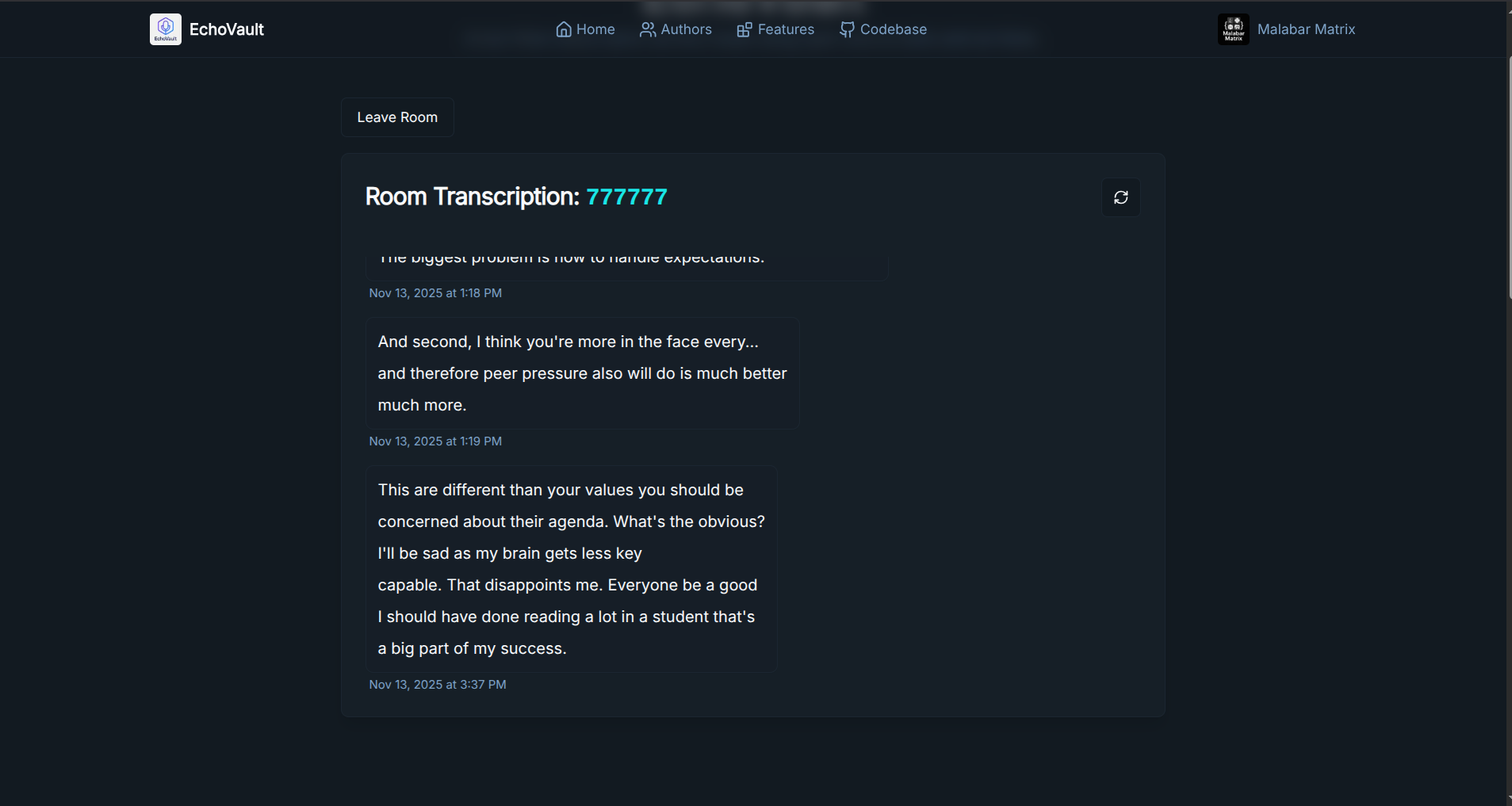
The frontend is a Next.js application that provides the user interface for viewing transcriptions. It uses a dedicated API route (/api/message) to receive new transcriptions from the Python backend, store them in MongoDB, and broadcast them using an event emitter. Another API route (/api/stream/[roomId]) uses Server-Sent Events (SSE) to stream live transcriptions to the connected clients, providing a real-time view of the captured audio.
End-to-End Workflow
- The user runs the Python script, configuring it to point to the Next.js API with a specific room ID.
- The script captures audio, transcribes it, and sends the text to the
/api/messageendpoint. - The Next.js server saves the message to MongoDB and emits a server-sent event.
- A user on the web app, connected to the
/api/stream/[roomId]endpoint, receives the event and sees the new transcription appear instantly.